한 에피소드에서 얻을 수 있는 보상 총합이 아니라 주어진 상태에서 미래에 얻을 수 있는 보상 총합을 구해야 함
수식으로 표현하면 할인율과 t번째 상태로 다음과 같이 나타낼 수 있으며 이를 이익(Return)이라 함 $$G_t = \sum_{k=0}^\infty \gamma^k R(S_{t+k+1})$$
$G_t$는 모든 행동이 일어났다고 가정한 다음 과거로 돌아가며 더한 값
특정 상태에서 갈 수 있는 전체 경로에 대한 평균, 이익의 기댓값을 구하면 그것이 특정 상태에서 미래에 얻을 수 있는 보상의 총합이 됨
이를 수식으로 표현하면 다음과 같으며, 이를 가치 함수(Value Function)라고 함$$V(s) = E[G_t|S_t = s]$$
보상, 이익, 가치 함수 개념 정리
명칭
개념
보상(R)
특정 상태에서 얻을 수 있는 즉각적인 피드백
이익(G)
한 에피소드의 특정 상태에서 종단 상태까지 받을 수 있는 보상 총합
가치 함수(V)
특정 상태로부터 기대할 수 있는 보상
벨만 방정식
벨만 방정식은 다음과 같음 $$V(s) = R(s) + (V(s'))$$
다음 상태의 가치로 현재 상태의 가치를 구함
현재 상태의 가치를 구하려 다음 상태를 계속 추적하므로 결국 종단 상태에 도달
이 방식으로 다음 상태를 따라가면 결국 종단 상태의 가치로 상태를 역추적하며 계산
종단 상태의 가치는 종단 상태의 보상과 같음
이를 코드로 구현하려면 '동적 계획법(Dynamic Programming)' 이라는 알고리즘을 사용
동적 계획법
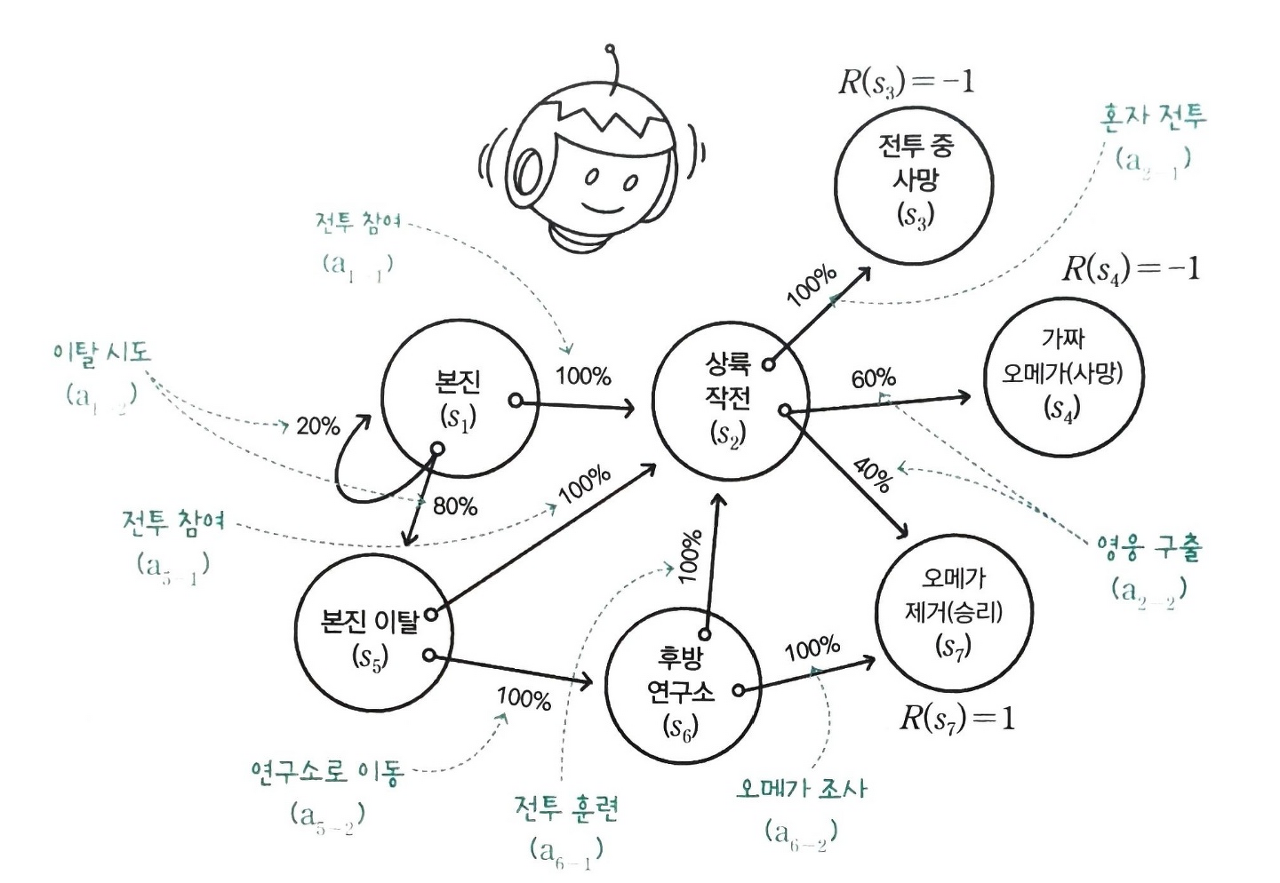
다음과 같은 예제가 있을 때, 동적 계획법을 적용해 봄
강화 학습 예제 (출처: Do it! 강화 학습 입문 도서)
가치를 구하려면 가치의 기대값을 알아야 하므로 가치 함수를 이용해 주어진 상태로부터 가능한 경로를 모두 거치며 보상을 계산해 봐야 함
위 예제에서는 종단 상태에서만 보상이 있기 때문에 다른 상태에서의 보상은 모두 0으로 초기화
종단 상태는 더 이상 상태 전이가 없으니 보상이 곧 가치가 됨
즉, $V(S3) = -1, V(S4) = -1, V(S7) = 1
이제 종단 상태와 인접한 상태인 S2, S6의 가치를 구해야 함
상태 $S2$에서 행동 $a_{2-1}$을 선택
$S3$로 전이할 확률: $P(S3|S2, a_{2-1}) = 1$
$S3$의 가치: -1
가치의 기대값: 가치 * 전이 확률 * 할인율 = $-1 * 1 * 0.9 = -0.9$
상태 $S2$에서 행동 $a_{2-2}$을 선택
$S4$로 전이할 확률: $P(S4|S2, a_{2-2}) = 0.6$
$S7$로 전이할 확률: $P(S7|S2, a_{2-2}) = 0.4$
$S4$의 가치: -1
$S7$의 가치: 1
가치의 기대값: $((-1 * 0.6) + (1 * 0.4)) * 0.9 = -0.18$
위의 설명을 알고리즘으로 표현하면 다음과 같음
1. 종단 상태를 제외한 모든 상태의 가치 $V(s)$를 0으로 초기화 2. 반복 카운터 $n$를 0으로 초기화 3. 반복: 반복 카운터 $n$을 1 증가 모든 상태 $s$에 대해 반복: 상태 $s$에서 취할 수 있는 모든 행동 $a$에 대해 반복: $s$에서 $a$를 취할 때의 모든 상태 전이 확률 $P(s'|s,\,a)$를 확인 $s$에서 $a$를 선택해 도달하는 다음 상태 $s'$의 가치 $V(s')$와 $P(s'|s,\,a)$를 곱함 도달 가능한 모든 상태 $s'$에 대해 $P(s'|s,\,a)\,\times\,V(s')$를 합산한 기댓값을 구함 모든 행동 $a$ 중 기댓값이 가장 큰 최적 행동 $a_*$를 확인 $a_*$의 기댓값에 할인율 $\gamma$를 곱하고, 상태 $s$의 보상 $R(s)$를 더한 값 $V_n(s)$를 구함 모든 $s$에 대해 $V_n(s)-V_{n-1}(s)$가 0을 만족하면 반복을 종료
할인율을 0.9로 가정하고 예제에 적용
S1
S2
S3
S4
S5
S6
S7
V0
0
0
-1
-1
0
0
1
V1
0
-0.18
-1
-1
0
0.9
1
V2
0
-0.18
-1
-1
0.81
0.9
1
V3
0.58
-0.18
-1
-1
0.81
0.9
1
V4
0.58
-0.18
-1
-1
0.81
0.9
1
이렇게 동적 계획법을 기반으로 가치 함수를 산출하는 방식을 '가치 반복법(Value Iteration)' 이라 함
모든 상태의 가치를 구했으니 이를 바탕으로 행동 선택이 가능
초기 상태 $s_1$에서는 $s_2$ 또는 $s_5$로 전이 가능
$s_5$의 가치가 더 크므로 $s_5$로 전이하는 행동인 $a_{1-2}$를 선택
$s_5$에서는 $s_2$ 또는 $s_6$으로 전이 가능
$s_6$의 가치가 더 크므로 $s_6$으로 전이하는 행동인 $a_{5-2}$를 선택
$s_6$에서는 $s_7$로 전이 가능
$s_7$로 전이
이렇듯 가치 함수를 모두 구하면 각 상태에 대해 미래 보상을 최대화 하는 최적 행동을 선택 가능
즉, 상태를 입력으로 받아 최적 행동을 출력하는 함수가 만들어진 것
이러한 함수를 정책(Policy)이라고 하며, 이 정책이 바로 강화 학습에서 구하고자 하는 목표