도서 정리/Do it! 강화 학습 입문
[Do it! 강화 학습 입문]4장. 딥레이서로 구현하는 자율 주행
dukh
2023. 8. 9. 09:29
본문의 모든 내용과 이미지의 저작권은 이지스퍼블리싱의 Do it! 강화 학습 입문 도서에 있습니다.
4-1. PPO 알고리즘 알아보기
1. PPO 알고리즘이란?
- PPO(Proximal Policy Optimization) 알고리즘은 2017년 OpenAI 팀이 발표한 논문 <근위 정책 최적화 알고리즘(Proximal Policy Optimization Algorithms)>에서 소개된 비교적 최신 기법
- 로봇 제어, 게임 등 다양한 강화 학습 과제에서 우수성을 입증했으며, 복잡한 난이도로 유명한 DOTA2라는 게임도 우수하게 플레이했음
- PPO 알고리즘이 발표된 이후 OpenAI는 대부분의 과제에 이 알고리즘을 사용했고, Unity ML과 딥레이서 등의 환경에서도 기본 알고리즘으로 사용
- PPO 알고리즘은 정책 경사(Policy Gradient) 방법에 해당, 정책 경사에 대한 공부가 필요
2. 정책 경사부터 PPO 알고리즘 이해 시작하기
- DQN이 가치 함수 또는 Q 함수를 업데이트하는 가치 반복법에 기초하는 반면, 정책 경사는 정책 반복법에 기초
- 정책 경사와 정책 반복법은 특정 상태에서 취하는 행동의 확률 분포로 이루어진 정책 네트워크(Policy Network)를 학습시킨다는 점에서 차이가 있음
- 상태를 입력으로 한다는 점에서 DQN의 신경망과 같지만, DQN의 출력이 Q 함수였다는 것과 대조적, 출력이 행동의 확률 분포라는 점에서 DQN에 비해 2가지 장점이 있음
DQN과 비교할 때 정책 경사의 장점
- DQN은 에이전트가 취할 수 있는 행동이 불연속한 경우에만 적용 가능 하지만, 정책 경사는 출력인 ‘확률 분포’를 ‘정규 분포’라 가정하고 샘플링을 진행하면 에이전트의 연속된 행동을 추출할 수 있음
- 정책 네트워크는 확률 분포를 기반으로 해서 행동을 선택하기 때문에 Q 학습과 같이 탐험을 위한 무작위성을 부여하는 엡실론과 같은 별도 계수가 필요하지 않음. 에이전트는 기존 정책을 그대로 준수하며 에피소드를 진행해도 무방. 따라서 정책 경사는 정책 이탈(Off-Policy)이 아닌 정책 밀착(On-Policy) 기법에 속함
정책 경사의 순서
- 정책 $\pi(\theta)$를 무작위로 생성($\theta$는 정책의 파라미터)
- 에이전트는 환경 내에서 $\pi(\theta)$에 따라 행동하며 확인한 일련의 상태와 보상을 샘플로 취함
- 특정 행동으로 인한 보상을 봄
- 특정 행동에 대한 보상이 기댓값보다 높으면 해당 행동의 확률을 증가시킴
- 특정 행동에 대한 보상이 기댓값보다 낮으면 해당 행동의 확률을 감소시킴
- 3을 반복하며 정책 파라미터 $\theta$를 조절
4-2. 딥레이서로 공부하는 강화 학습
1. 딥레이서 차량 설정하기
회원 가입 후 로그인하기
- 딥레이서 공식 홈페이지에 접속해 회원 가입 후, 로그인
- https://aws.amazon.com/ko/deepracer/
- 신용카드 번호를 묻지만, 무료 플랜을 사용하면 결제되지 않으니 안심하고 진행
콘솔에 로그인하고 지역을 바꾼 뒤 딥레이서 서비스 선택하기

- 오른쪽 상단의 ‘콘솔에 로그인’ 버튼 클릭

- 국가를 ‘미국 동부(버지니아 동부)’로 설정

- 상단 검색창에 ‘DeepRacer’를 검색하여 AWS DeepRacer로 접속
차고에 들어가 차량 설정하기

- 좌측 메뉴의 ‘Your garage’ 버튼을 클릭해 차고로 이동

- 우측 상단의 ‘Build new vehicle’ 버튼 클릭

- 자동차의 이름, 색 지정 후, 다음 클릭

- 단일 카메라로 지정 후, ‘완료’ 클릭
카메라를 여러 개 조합하면 장애물 회피와 같은 복잡한 과제를 잘 수행할 수 있지만, 그만큼 학습 시간이 길어지고 학습 수렴도도 낮아짐 그래서 시간 단축을 위한 타임 트라이얼류 과제는 단일 카메라로 훈련할 때 더 좋은 성능을 내는 것으로 알려져 있음
2. 딥레이서 모델 만들고 학습시키기
모델 생성 화면으로 이동하기

- 우측 상단의 ‘Create model’ 버튼 클릭
모델 이름 지정하기

- 모델 이름은 64자까지 사용 가능
시뮬레이션 환경 설정하기

- 딥레이서를 처음 시도해볼 땐, ‘The 2019 DeepRacer Championship Cup’과 같이 트랙 너비가 넓고 단순한 코스를 추천
경주 종류 선택하기
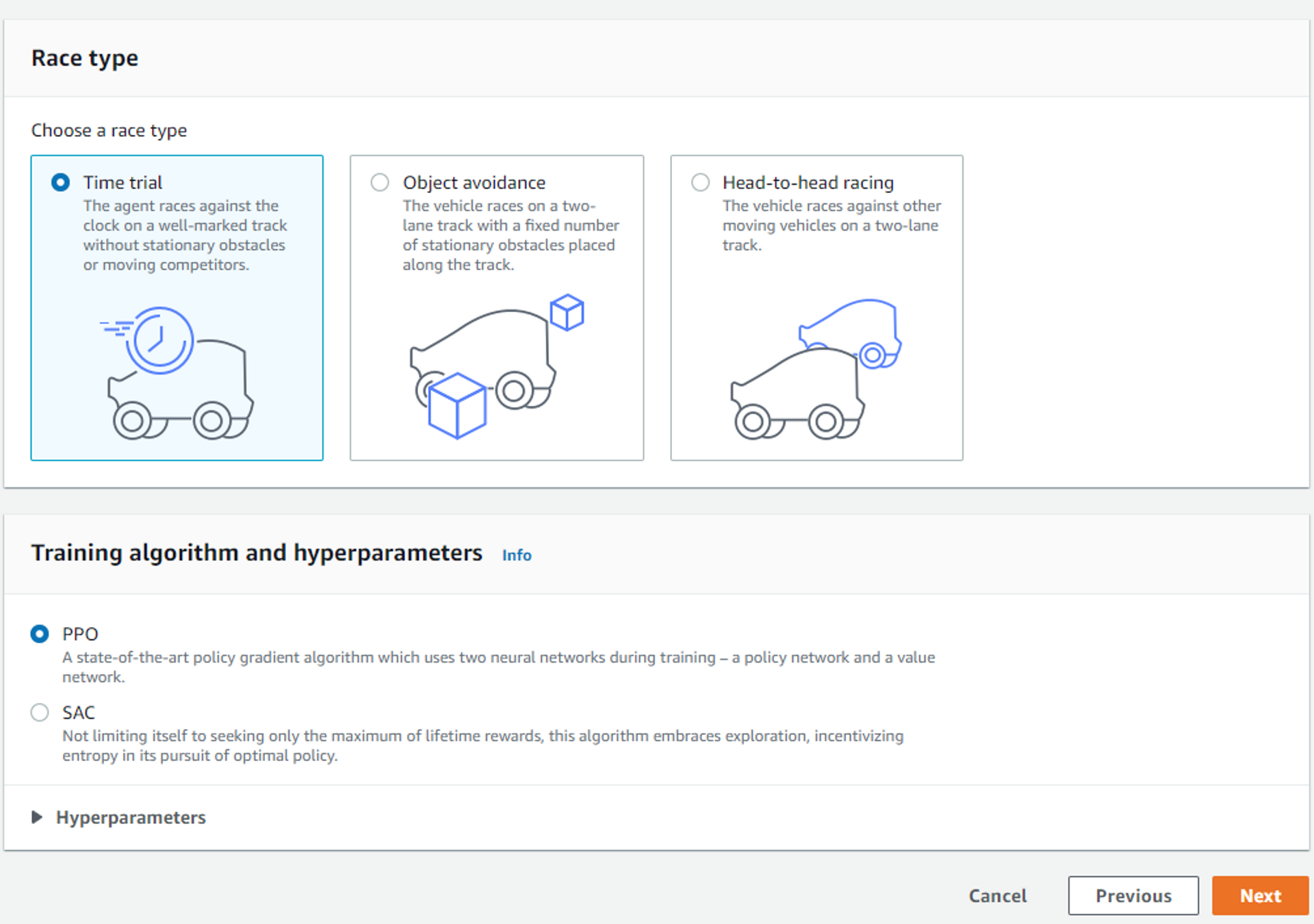
- 레이스 타입은 ‘Time Trial’, 학습 알고리즘은 ‘PPO’ 선택
차량 행동 공간 설정하기
- 행동 공간은 연속(continuous), 불연속(discrete) 방식 중에서 선택 가능
- PPO와 같은 정책 경사 방법은 에이전트의 연속되는 행동을 추출할 수 있다는 장점이 있으므로 에이전트의 행동을 둘 중 하나로 설정할 수 있음

- 행동 공간을 ‘Discrete action space’로 설정
- 조향각 세분을 ‘3’, 최대 조향각을 ‘30도’로 설정
- 속도 세분을 ‘1’, 최대 속도를 ‘3’으로 설정
모델을 적용할 차량 선택
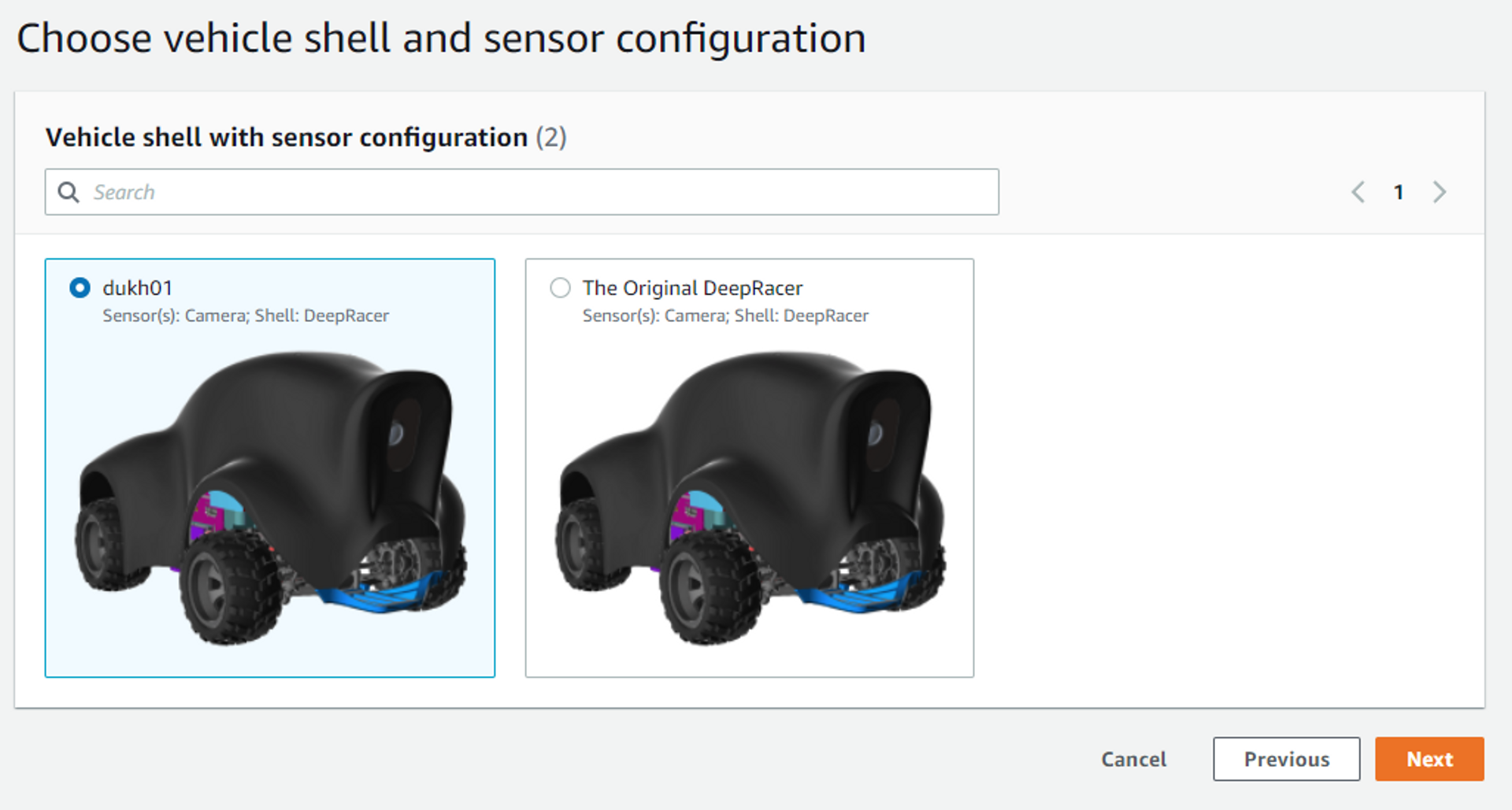
- 만들어둔 차량을 선택하고 ‘다음’ 클릭
보상 함수 살펴보기
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# 중앙선으로부터 거리 계산
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# 중앙선에 가깝게 달릴수록 더 높은 보상을 줌
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # 도로밖을 벗어나거나 부딫히면 보상을 잃음
return float(reward)3. 딥레이서 실행하기
훈련 초기화한 후 에이전트가 트랙을 달리는 모습 확인하기
- 위의 모든 설정 단계를 마치면 훈련 창이 나타남
- 훈련은 바로 시작되지 않으며, 훈련을 초기화하는 데 10분 정도 소요


- 초기화가 완료되고 학습이 시작되면, 차량의 움직임을 비디오로 확인 가능
- 보상 그래프도 실시간으로 확인 가능
- 훈련이 끝날때까지 대기

- 훈련이 끝나면, 모델 개선이 가능.
- 하단의 ‘Start evaluation’ 버튼을 눌러 모델 개선 진행
- 모델 개선은 다른 트랙에서 진행이 가능하지만, 동일한 환경에서 시험해보기 위해 동일한 트랙 선택

- 완주를 하지 못했고, 학습이 잘 못 되었다는 것을 확인 가능, 파라미터 수정이 필요
- 즉, 강화 학습은 파라미터에 매우 민감, 적절한 파라미터 설정이 필요