도서 정리/Do it! 강화 학습 입문
[Do it! 강화 학습 입문]3장. 알파고 도전을 위한 첫걸음
dukh
2023. 7. 6. 11:36
본문의 모든 내용과 이미지의 저작권은 이지스퍼블리싱의 Do it! 강화 학습 입문 도서에 있습니다.
3-1. 게임을 스스로 플레이하는 에이전트 만들기
- 강화 학습을 게임 환경에서 공부하는 이유
- 현실에서는 환경 통제가 거의 불가능하기 때문
- 현실에서 사용하기 위해선, 강화 학습 에이전트과의 상호 작용을 위해 로봇 같은 새로운 분야도 공부해야 함
- 에이전트, 환경, 보상을 통제하기 쉽고 실습할 때 입력해야 하는 코드의 양도 적음
- 게임 환경은 강화 학습 공부에 있어 최고의 환경인 셈
- 현실에서는 환경 통제가 거의 불가능하기 때문
1. OpenAI Gym 레트로를 위한 환경 준비하기
OpenAI Gym 레트로 환경 준비하기
- 지원하는 OS 목록
- 윈도우 7, 8, 10
- macOS 10.12(시에라), 10.13(하이 시에라), 10.14(모하비)
- Linux(manylinux1)
- 지원하는 파이썬 버전
- 3.5, 3.6, 3.7
OpenAI Gym 레트로가 지원하는 게임 환경 살펴보기
ℹ️ OpenAI Gym 레트로는 1,000개가 넘는 게임을 지원
- 아타리 게임기
- 아타리 2600(Stella)
- PC 엔진(NEC)
- TurboGrafx-16/PC Engine(Mednafen/Beetle PCE Fast)
- 닌텐도 계열
- 게임보이/게임보이 컬러(gambatte)
- 게임보이 어드밴스(mGBA)
- 패미컴 NES(FCEUmm)
- 슈퍼 패미컴 SNES(Snes9x)
- 세가 계열
- 게임 기어(Genesis Plus GX)
- 메가 드라이브(Genesis Plus GX)
- 마스터 시스템(Genesis Plus GX)
- 게임 환경은 ‘에뮬레이터(Emulator)’라고 하며, 게임은 ‘롬 파일(ROM File)’ 이라고 함
- 에뮬레이터는 인터넷에서 구하기 쉬운 반면, 롬 파일은 라이선스가 적용되므로 게임 판매 사이트를 이용해 구매해야 함
- OpenAI Gym 레트로는 실습을 위한 비상업용 롬 파일을 제공하기 때문에 사용해도 괜찮음
2. 에어스트라이커 게임 실행하기
깃허브 클론하기
- 깃허브 저장소를 클론하여 개발 환경을 설정
git clone <https://github.com/yunho0130/start-RL>콘다 환경 만들고 종속성 라이브러리 설치하기
- 다음 명령어를 입력하여 새 콘다 환경을 만들고 종속성 라이브러리 설치
# 클론한 깃허브 저장소의 gym-retro 폴더로 이동
cd gym-retro
# 파이썬 개발 환경 설정 정보가 들어 있는 environment.yml 파일 참조. 새 콘다 환경 생성
conda env create -f environment.yml # 1~2시간 소요
# 콘다 환경 활성화
conda activate rl-gym-retro게임 환경 설치 확인하고 게임 실행해 보기
- 다음 명령어를 입력하여 Airstriker 게임 실행
- 게임은 방향키로 움직이고 X 키로 총을 쏨
python -m retro.examples.interactive --game Airstriker-Genesis- 게임이 실행된다면 정상적으로 개발 환경 설정이 완료된 것
- 실행되지 않는다면 개발 환경 재설정, 혹은 Anaconda Prompt에서 실행
게임 실행 데이터 살펴보기

- 게임을 플레이하고 터미널을 보면 게임의 데이터가 출력되었음을 확인 가능
- 이 데이터는 에이전트의 정보를 요약한 것
- steps/episode_steps : 게임이 얼마나 진행되었는지를 의미
- episode_returns_delta : 어떤 행동에서 얼마나 큰 점수를 얻었는지를 의미
- episode_returns : 누적 점수
- 이 플레이 데이터를 바탕으로 에이전트를 학습시킬 수 있음
에이전트 학습시켜 보기
- 현재 환경에서는 에이전트가 누적 점수를 최대화하도록 학습시켜 볼 수 있음
- gym-retro 디렉터리로 이동 후, 다음 명령어를 실행하여 에이전트 학습 진행
python -m random_agent

- 작은 화면으로 알아서 플레이하는 게임이 실행 됨
컴퓨터가 어떻게 게임을 플레이했는지 살펴보기
ℹ️ random_agent.py 를 기반으로 게임을 플레이하고 있기 때문에 코드를 읽어보면 알 수 있다.
import retro # OpenAI Gym 레트로 임포트
def main():
env = retro.make(game='Airstriker-Genesis') # 게임 불러오기
obs = env.reset() # 게임 환경 초기화
while True: # 반복
obs, rew, done, info = env.step(env.action_space.sample()) # 무작위 동작 액션 샘플 적용
env.render()
if done:
obs = env.reset() # 게임 종료 및 환경 초기화
env.close()
if __name__ == "__main__":
main()3. 브루트 포스 접근법으로 에이전트 훈련시키기
- 앞의 실습으로는 강화 학습이 어떻게 진행되는지, 어떤 데이터를 기준으로 학습하는지 등을 살펴보기 어려움
로그로 강화 학습 과정 들여다보고 에이전트 학습시키기
- 다음 명령어를 입력하면 게임이 실행되고 터미널에 로그가 출력되게 할 수 있음
python -m retro.examples.random_agent --game Airstriker-Genesis

- ‘press enter to continue’ 메시지와 함께 잠시 동안 멈춰 있음
- 에이전트가 생존한 시간, 얻은 점수를 고려하여 강화 학습 모델을 훈련시킬 것인지 묻는 것
- 로그를 살펴보면 random_agent, 즉 무작위로 움직이는 정책을 사용했지만 total reward는 점점 증가하는 것을 알 수 있음
- 이는 정책을 정하지 않아도 에이전트를 훈련시킬 수 있음을 의미
- 무작위로 조작하며 가장 긴 시간 생존하면서 점수가 높은 에이전트를 남기는 방식으로 모델을 훈련시킬 수 있다는 뜻
- 이와 같은 접근 방식을 브루트 포스$^{Brute\,Force}$ 접근법이라고 함
브루트 포스 접근법으로 에이전트 여러 번 훈련시키기
- 다음 명령어를 입력하여 브루트 포스 접근법으로 강화 학습 에이전트를 훈련시킬 수 있음
python -m brute --game Airstriker-Genesis
- 최고 점수를 기록한 에이전트로 발전해 나가는 것을 확인할 수 있음
- 최고 점수가 갱신될 때 마다 해당 에이전트의 플레이 기록을 남김
- 실제 브루트 포스 접근법으로 에이전트를 훈련시키려면 1~2일 이상이 소요
- 즉, 브루트 포스 접근법은 비효율적임
코드 살펴보기
import random
import argparse
import numpy as np
import retro
import gym
# 탐색 매개변수
EXPLORATION_PARAM = 0.005
# 프레임 스킵 클래스
class Frameskip(gym.Wrapper):
def __init__(self, env, skip=4):
super().__init__(env)
self._skip = skip
def reset(self):
return self.env.reset()
def step(self, act):
total_rew = 0.0
done = None
for i in range(self._skip):
obs, rew, done, info = self.env.step(act)
total_rew += rew
if done:
break
return obs, total_rew, done, info- 탐색 매개변수란, 새로운 탐험을 어느 정도로 할지 정하는 변수
- 에이전트가 새로운 활동을 하면 할수록 높은 보상을 주는 원리로 동작
- 강화 학습 에이전트의 호기심 정도라고 생각하면 됨
- Frameskip 클래스는 실제 게임 플레이를 컴퓨터가 진행하므로 프레임을 줄이는 클래스
- 연산 부담을 줄이고 게임 진행 속도를 높일 수 있음
# 최대 에피소드를 제한하는 역할을 하는 클래스
class TimeLimit(gym.Wrapper):
def __init__(self, env, max_episode_steps=None):
super().__init__(env)
self._max_episode_steps = max_episode_steps
self._elapsed_steps = 0
def step(self, ac):
observation, reward, done, info = self.env.step(ac)
self._elapsed_steps += 1
if self._elapsed_steps >= self._max_episode_steps:
done = True
info['TimeLimit.truncated'] = True
return observation, reward, done, info
def reset(self, **kwargs):
self._elapsed_steps = 0
return self.env.reset(**kwargs)
# 각 행동의 지점을 의미하는 노드 클래스
class Node:
def __init__(self, value=-np.inf, children=None):
self.value = value
self.visits = 0
self.children = {} if children is None else children
def __repr__(self):
return "<Node value=%f visits=%d len(children)=%d>" % (
self.value,
self.visits,
len(self.children),
)- 계속 학습을 진행하면 끝나지 않기 때문에 TimeLimit 클래스에서 최대 에피소드를 제한
- Node 클래스는 트리 형태로 탐색할 수 있는 각 행동의 지점을 의미
# 액션 선택 함수
def select_actions(root, action_space, max_episode_steps):
node = root
acts = []
steps = 0
while steps < max_episode_steps:
if node is None:
# 무작위 탐색, 기존 트리 탐색이 끝나면 무작위 액션을 선택
act = action_space.sample()
else:
epsilon = EXPLORATION_PARAM / np.log(node.visits + 2)
if random.random() < epsilon:
# 탐색 매개변수의 값에 따라 무작위 행동
act = action_space.sample()
else:
# greedy action
act_value = {}
for act in range(action_space.n):
if node is not None and act in node.children:
act_value[act] = node.children[act].value
else:
act_value[act] = -np.inf
best_value = max(act_value.values())
best_acts = [
act for act, value in act_value.items() if value == best_value
]
act = random.choice(best_acts)
if act in node.children:
node = node.children[act]
else:
node = None
acts.append(act)
steps += 1
return acts
# 그동안 플레이한 데이터와 트리 업데이트
def update_tree(root, executed_acts, total_rew):
root.value = max(total_rew, root.value)
root.visits += 1
new_nodes = 0
node = root
for step, act in enumerate(executed_acts):
if act not in node.children:
node.children[act] = Node()
new_nodes += 1
node = node.children[act]
node.value = max(total_rew, node.value)
node.visits += 1
return new_nodes- selection_action()는 각 트리에서 액션을 선택하는 함수
- 장기 보상은 고려하지 않고 가장 높은 보상을 지닌 하위 노드를 선택하도록 탐욕 알고리즘(Greedy Algorithm)을 사용
- 에이전트가 얼마나 오래 생존했는지, 얼마나 많은 적을 없앴는지를 기준으로만 행동을 선택
- 앞으로 얼마나 더 살 수 있을지는 고려하지 않음
- update_tree()는 그동안 플레이한 데이터와 함께 트리를 업데이트
- 어떤 상황에서 어떤 행동을 취했는지를 저장
# 롤아웃 함수
def rollout(env, acts):
total_rew = 0
env.reset()
steps = 0
for act in acts:
_obs, rew, done, _info = env.step(act)
steps += 1
total_rew += rew
if done:
break
return steps, total_rew- rollout() 함수에서 환경과 진행 데이터를 초기화하고 더 이상 행동을 취할 수 없을 때까지 행동을 진행한 뒤, 마지막에 진행한 steps와 최종 보상값을 반환
class Brute:
def __init__(self, env, max_episode_steps):
self.node_count = 1
self._root = Node()
self._env = env
self._max_episode_steps = max_episode_steps
# 실행 함수
def run(self):
acts = select_actions(self._root, self._env.action_space, self._max_episode_steps)
steps, total_rew = rollout(self._env, acts)
executed_acts = acts[:steps]
self.node_count += update_tree(self._root, executed_acts, total_rew)
return executed_acts, total_rew
- run()는 액션을 선택하고 롤아웃을 진행하는 함수
- 에이전트가 게임을 플레이한 결과를 트리에 업데이트한 뒤, 그 결과를 반환
# 훈련 진행 조건 설정
def brute_retro(
game,
max_episode_steps=1000,
timestep_limit=1e5,
state=retro.State.DEFAULT,
scenario=None,
):
env = retro.make(game, state, use_restricted_actions=retro.Actions.DISCRETE, scenario=scenario)
env = Frameskip(env)
env = TimeLimit(env, max_episode_steps=max_episode_steps)
brute = Brute(env, max_episode_steps=max_episode_steps)
timesteps = 0
best_rew = float('-inf')
while True:
acts, rew = brute.run()
timesteps += len(acts)
# 최고 기록이 갱신될 때 플레이 데이터를 기록
if rew > best_rew:
print("New best reward {} => {}, Timesteps: {}".format(best_rew, rew, timesteps))
best_rew = rew
env.unwrapped.record_movie("best_brute.bk2")
env.reset()
for act in acts:
env.step(act)
env.unwrapped.stop_record()
if timesteps > timestep_limit:
print("timestep limit exceeded")
break
# 메인 함수
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--game', default='Airstriker-Genesis')
parser.add_argument('--state', default=retro.State.DEFAULT)
parser.add_argument('--scenario', default=None)
args = parser.parse_args()
brute_retro(game=args.game, state=args.state, scenario=args.scenario)
if __name__ == "__main__":
main()- brute_retro() 함수는 timestep_limit, 최대 에피소드 제한 등 훈련 진행 조건을 설정하고 훈련에서 가장 좋은 기록을 남긴 모델의 플레이 데이터를 저장
- 메인 함수에서는 brute_retro() 함수를 호출해 훈련을 진행
- 게임 종류, 상탯값, 시나리오 정보를 인자로 받아 코드를 유연하게 호출해 훈련을 진행하도록 구성
4. OpenAI Baselines로 더 쉽게 훈련시키기
ℹ️ OpenAI Baselines는 OpenAI에서 지금까지 출시한 모델 중에서 가장 성능이 좋은 것만 모아 정한 기준점
- 다양한 강화 학습 정책과 알고리즘을 쉽게 적용 가능하며, 여러 게임 환경에서 실험 가능
- 자신이 훈련하고 싶은 게임 환경과 적용하고 싶은 알고리즘만 알면 코드 1줄로도 훈련 진행 가능
5. OpenAI Baselines 환경 설정하기
❗ OpenAI Baselines를 설치하려면 다양한 종속성 패키지 설치가 필요
MuJoCo 설치하기
- MuJoCo는 시뮬레이터로 보통 물리 실험에 사용되며 유료 서비스였지만, DeepMind 사에서 2.1.0 버전을 무료로 공개

- 터미널에서 다음 명령어를 입력하여 MuJoCo 설치
pip install mujoco-py
Open MPI 설치하기
- Open MPI(Message Passing Interface)는 오픈소스로 공개된 고성능 메시지 전달 인터페이스로 분산 병렬 컴퓨팅에 사용되는 API
- 다음 명령어를 입력하여 cmake와 Open MPI 설치
pip install cmake mpi4py
OpenAI Baselines 설치하기
- 다음 명령어를 입력하여 OpenAI Baselines 저장소 클론
git clone <https://github.com/openai/baselines.git>
- 다음 명령어를 입력하여 baselines 폴더로 이동
cd baselines
- 다음 명령어를 입력하여 tensorflow 설치
# GPU가 없다면
pip install tensorflow==1.14
# Cuda를 지원하는 GPU가 있다면
pip install tensorflow-gpu==1.14
- 다음 명령어를 입력하여 다운받은 baselines 패키지 설치
pip install -e.
- 모든 과정을 마쳤으면 이제 환경 구성이 완료된 것
6. OpenAI Baselines 사용해 보기
에이전트 훈련하는 방법 살펴보기
- 다음 한줄의 명령어로 강화 학습 진행 가능
python -m baselines.run -alg={사용할 알고리즘} --env={환경 id} --{그 외 옵션}
OpenAI Baselines로 에이전트 훈련시켜 보기
- 다음 과정을 통해 로그 포맷 지정
👉🏻 baselines - baselines 디렉터리의 logger.py 의 391번째 줄의 코드를 다음과 같이 수정

- 다음 명령어를 입력해 카트폴(CartPole) 게임을 PPO2 알고리즘으로 훈련시켜볼 수 있음
# CartPole-v1을 PPO2 알고리즘을 사용해 2e5동안 학습
python -m baselines.run --alg=ppo2 --env=CartPole-v1 --num_timesteps=2e5
--save_path=./models/cartpole_ppo2 --log_path=./logs/

- --num_timesteps: 훈련을 얼마나 오래 진행할지 지정
- --save_path: 모델의 저장 경로를 지정
- --log_path: 모델 훈련과 성능 정보를 기록하는 로그의 저장 경로를 지정
- 훈련 과정 지표훈련 과정 지표 설명
eplenmean(mean episode length) 평균 에피소드 길이 eprewmean(mean reward per episode) 평균 에피소드 보상 fps(frames per second) 초당 게임 화면 프레임 수 loss/approxkl 손실 근삿값(KL loss라고도 함) loss/clipfrac 하나의 클립 범위에서 하이퍼파라미터를 사용하는 비율 loss/policy_entropy 정책의 엔트로피 값 loss/policy_loss 정책 함수의 손실값 loss/value_loss 가치 함수의 손실값 misc/explained_variance 설명된 분산값(0보다 작거나 같으면 제대로 예측되는 것) misc/nupdates timesteps를 배치 수로 나눈 값 misc/serial_timesteps 총 timesteps를 환경 종류 개수로 나눈 수(여러 환경의 경우) misc/time_elapsed 총 걸린 시간(초 단위) misc/total_timesteps 총 timesteps 수
텐서보드로 훈련 상황 확인하기
- 다음 명령어를 실행하여 텐서보드로 로그 시각화
# logs 폴더 내의 텐서보드를 읽어옴
tensorboard --logdir=./logs/
- 웹 브라우저에서 localhost:6006 에 접속하여 그래프 확인
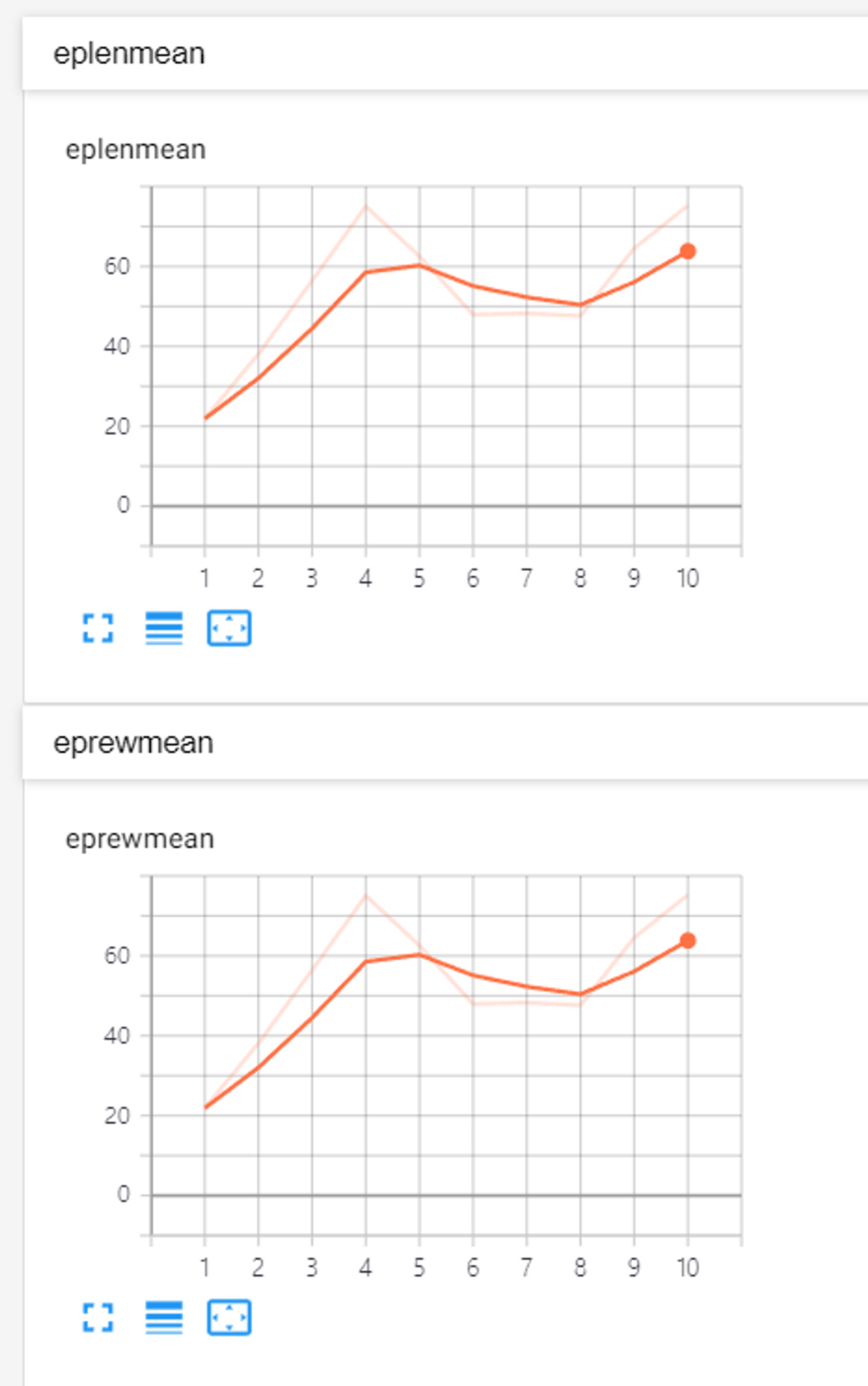
- 에피소드 평균 길이와 보상이 모두 증가되는 것을 확인 가능
모델 훈련이 잘 됐는지 확인해 보기
- 다음 명령어를 입력하면 훈련된 모델로 게임을 실시간으로 플레이하는 것을 확인 가능
python -m baselines.run --alg=ppo2 --env=CartPole-v1 --num_timesteps=0
--load_path=./models/cartpole_ppo2 --play
3-2. 현실 세계에서의 강화 학습
- 점차 현실에 가까운 시뮬레이터 환경이 갖춰지고 있으므로, 그 환경에서 훈련한 모델이라면 현실에서도 의미가 있음
- 특히 강화 학습을 적용한 로봇 공학 분야는 앞으로도 발전 가능성이 커서 주목받고 있음
강화 학습을 공부하는 것이 중요한 이유
- 새로운 기술이 실제 사업 모델에 적용되어 시장에서 좋은 반응을 이끌어 내고 있음
- 강화 학습은 현실 시장에서도 주목받고 있을 뿐 아니라 앞으로도 다양한 기회를 제공할 것